摘要:
論文論述了利用機器學習的相關技術,整合監督相關數據,提取在押人員和歷史人員的相關特征和風險評估表特征,利用大數據、機器學習、深度學習技術,研發和建設了一套監所人員風險評估算法模型。
大數據是一種手段,并不能無所不包、無所不用。研究并利用大數據技術的根本目的在于用好數據,通過挖掘海量數據中的隱藏價值,實現數據賦能業務。大數據建模本質上是一個機器學習的過程,機器學習是一門研究怎樣使用數據思維解決問題的學科,它的原理和人類思維非常相似,人類是基于經驗對規律進行總結和歸納,而機器(計算機)則是基于數據(即經驗的外在體現),利用算法來總結規律,并作出預測。
當前,信息技術、網絡技術已經進入了各行各業,現代社會治安隱患、新型犯罪活動等也更加智能化、隱蔽化,甚至出現了許多高科技犯罪手法,被動搜集信息的公安警務工作模式已經跟不上社會發展的腳步,而將大數據智能化技術深入應用,可以有效提高公安機關的打擊犯罪能力、保障社會安全的能力!
本篇論文刊登于《警察技術》2022年第1期
本文由杭州中奧科技有限公司(北京研究院、數據智能部)、公安部第一研究所聯合編寫。
關鍵詞:風險評估預警模型、機器學習、半監督、支持向量機、K近鄰、隨機森林
一、背景
我國目前的監獄人員管理現狀,多數還停留在以獄警巡查加攝像機監視報警的階段,人工作業仍占絕大比重,信息化程度比較低。
為提高監管風險識別水平,我們可以利用機器學習的相關技術,整合監管方面的相關數據,提取服刑人員相關特征和風險評估表,利用大數據、數據庫處理技術、計算機軟件技術、地理信息系統技術、互聯網技術等多學科能力,研發和建設了這套獄所人員的風險評估算法模型,實現監所管理信息化,檢索的智能化。
二、模型構建相關技術
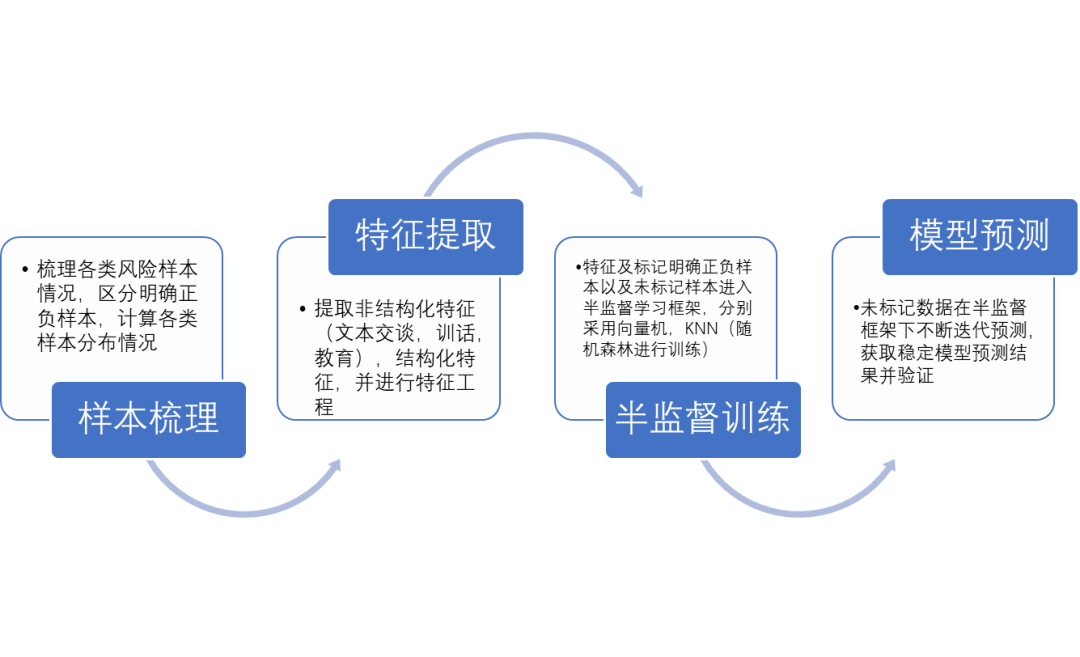
2.1 模型整體框架
在傳統機器學習行業中,無標簽的數據易于獲取,而有標簽的數據收集起來通常很困難,標注也耗時和耗力。在這種情況下,半監督學習更適用于現實世界中的應用。
在分辨監所人員風險訓練樣本時,我們只能通過以往人員犯事記錄進行風險標記,對于那些沒有明顯表征,但潛在存在風險的人員我們缺無法完全標記為無風險白樣本。
本模型是一種基于半監督學習框架的特征向量學習預測模型方法
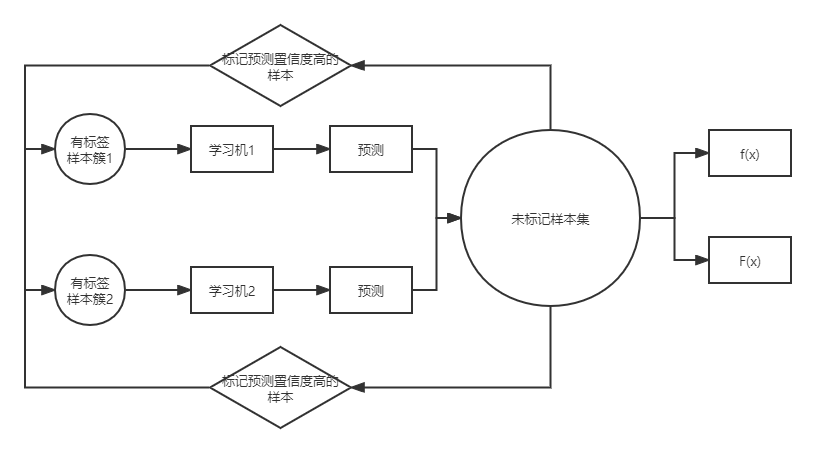
圖2 半監督學習架構圖
2.2 模型特征提取
采用模型的特征在已知結構化特征提取的基礎上增加非結構化特征提取。結構化特征提取在行業內常用成熟。
一般簡單的非結構化特征提取采用正則+規則的形式,往往用在身份證號,生日,手機號等規則的實體提取場景采用,但在本場景中,監所數據中非結構化特征大量存在于談話記錄,教育記錄,歷史檔案等復雜文本當中,提取的體征也較身份證號這類實體復雜。
因此我們采用基于深度學習的命名實體識別技術BERT+CRF(神經網絡進行提取。BERT使用Transformer作為獲取文本表征的手段(主要依賴了多頭的self-attention機制, 見圖3), 能夠獲取比BiLstm更深層次的語言表征。
基于谷歌預訓練的中文BERT模型, 結合我們的命名實體識別任務(針對特定場景的標注和訓練), 在保證模型有較強泛能力的同時, 提升特定場景下的模型準確率。使用BERT提取文本向量特征后,與結構化特征一起構建人員特征寬表待進入半監督模型訓練。
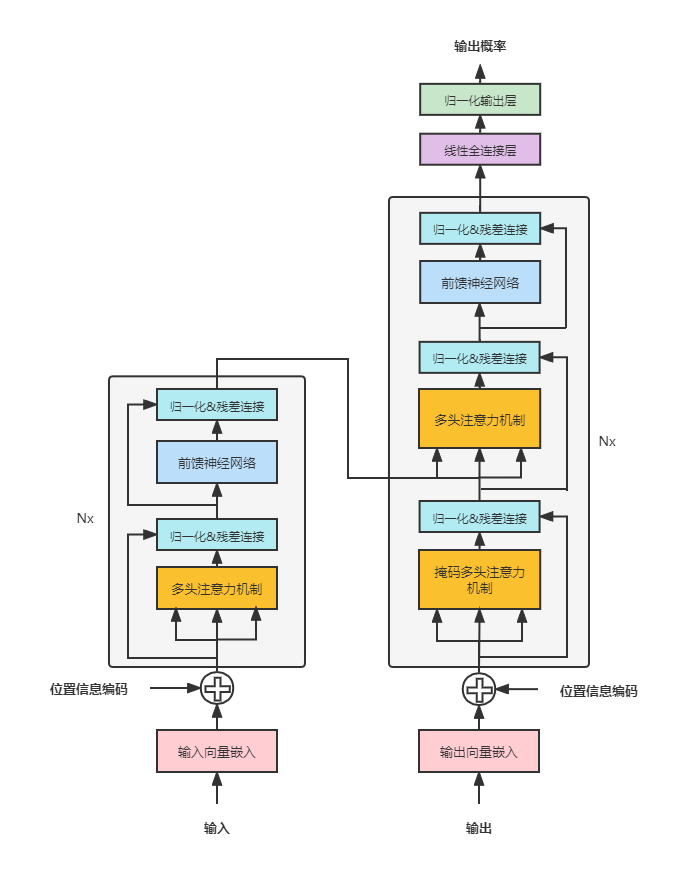
圖3 BERT Transform框架
三、數據的分析及處理
3.1 數據特征篩選
參考數據庫表和表內數據,提取健康、鬧監、心理等六個模型的關鍵屬性,摘取模型訓練所需的特征維度。
在押危險人員具備區別于普通在押人員的一些特點和活動規律。通過針對所需要分析的目標人群的背景信息、案件信息、獎懲信息、就醫信息、健康情況、違紀違規等數據加上人員在押生活中記錄的如談話記錄、教育記錄,案件案情,客觀評價等非結構化文本類信息,提取出多維度的特征標簽形成特征寬表,通過模型訓練結合業務角度從在押人員中挖掘出潛在的高風險人員。
3.2 數據預處理
針對特征進行歸一化處理,z-score歸一化轉化為0-1之間的數值,使得各個特征在同一度量維度下,從而使它們之間的權重更好處理。此外,采用利用均值和標準差對數值進行歸一化,針對年齡、同行次數等連續型特征進行離散化,將其等頻離散化/等區間離散化處理,降低算法對于分布假設的依賴性。
針對每個數值型特征,結合特征的分布及與目標分類的分布情況,對于特征進行數學變化,比如次方,三次方,取自然對數等數學變換。
3.3 特征向量數據平滑處理
進行特征向量提取和表示時,并不是每個特征值在每個維度都有數值,經常該字段為空值或者缺失,當詞匯在某個維度未出現時,記錄該特征點時用0來表示,但是該特征對應的特征向量就會出現一個斷點,這對模型訓練和結果分析時造成了很大困難,需要對特征進行修正,以達到能符合后續處理的需要。本文采用滑動平均值來處理數值斷點問題。
3.4 特征向量人工標注
于模型訓練的特征數據需要人工進行標注,數據有了標簽,機器才可以根據帶有標簽的數據進行模型訓練,數據標注標準采用是否有風險進行標注,即對數據的多個維度進行人工綜合分析,并判斷該犯人是否有健康、鬧監、心理等六個方向的風險,標注人員為具有多年看守所工作經驗的預警,標注人員只需要根據犯人的特征數據表中的信息,在上述的健康、鬧監、心理等六個方向上打上是或否的標記,是表示該犯人具有該方向的風險,而否表示該犯人無該方向的風險。
四、半監督學習模型訓練
4.1 不同類別基分類器模型選擇
在進行健康、鬧監、心理等六個模型訓練時,由于特征數據的維度和疏密程度不同,所以采用的機器學習框架不同。根據數據和風險評估的最終效果,選取了K近鄰算法、支持向量機模型和隨機森林模型。
4.2 實驗結果與分析
在對健康、鬧監、心理等6個模型進行五輪交叉驗證模型訓練后,利用訓練好的模型對測試數據進行預測,計算得到每個模型的準確率(ACC)和召回率(REC)。綜合評估,六個模型平均的準確率和召回率達到80%以上,當在訓練數據積累較多時,特征維度較為豐富時,使用非距離計算的樹形模型具有較好的泛化性。
如今信息化智能化已在遍地開花,機器學習技術已日趨成熟,已在金融、軍事、政府、公安等各個領域應用廣泛。看守所和監獄這類監管的行業更加需要信息化注入新的力量,以便于更好的為社會主義建設服務。而人工智能在監管領域落地,更進一步說明信息化建設迫在眉睫。因此,機器學習和人工智能在監獄行業的落地具有重要意義。
本文提出了一種基于半監督學習的監所獄所風險人員評估的計算方法,也總結了具體的遠程,針對不同種類特征數據不同機器學習訓練模型的優劣。對于在模型訓練過程中人工標注數據較少,特征向量中缺失值較多的情況,某些人員的特征性質可能并沒有在數據特征層面取得較好的體現。在將來的研究中,需要更加細致的統計人員的相關特征,這樣才能更加細致的體現風險評估的準確性。
本篇論文刊登于《警察技術》2022年第1期
全國統一客服熱線


 浙公網安備 33010502007057號
浙公網安備 33010502007057號
